I’ve recently been investigating the command-line utility zfec, which is a lot like the UNIX “split” utility, except, using a technique called erasure coding, you can choose to split your file into M pieces, any K of which are enough to recreate the file using the complimentary [sic] zunfec command.
Concrete example: a 100K file can be split into 10 (or more) pieces, each just over 25K long, and zunfec can recreate the original from any 4 of them.
Any 4. You might expect this to incur a lot of overhead in each piece, but it turns out it’s just a header of four bytes or less. Pretty much the same as cutting the file into pieces.
This amazed me. How could this possible work? How can you split data into M pieces so that any K of them is enough to reconstruct them? Linear algebra to the rescue!
Suppose we want to encode a twelve character text string into a bunch of arrays, each with four values, any three of which are sufficient to reconstruct the original. Let’s use the string “Lovefromdawn”. Here’s what you do:
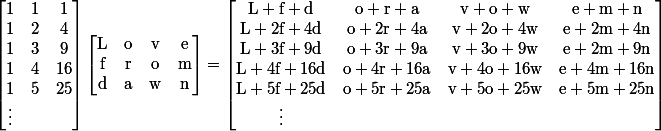
The matrix furthest to the left is a Vandermonde matrix, which is a matrix where each row forms a geometric series starting with 1. A square Vandermonde matrix has the special property that as long as the second column has no repeated elements, the matrix is invertible (and in fact, there is a special algorithm to invert it quickly).
The split pieces correspond to rows of the matrix on the right. Choose any three of them; let’s say row 1, 2 and 4. Once we know what row numbers they are (and this explains the tiny header), we get the following system of equations:
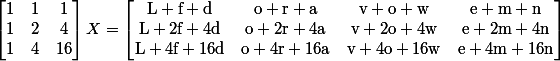
We know the leftmost matrix is invertible, so multiply both sides by the inverse, and we solve for X, recovering “Lovefromdawn”. Wowza!
But wait! One problem remains: if we use standard integer arithmetic, the matrix on the right ends up with a lot of values larger than 255, and we can’t store it in a byte array. That ain’t no good.
Luckily, it turns out that most theorems dealing with matrices and invertibility only assume we are operating over an arbitrary field, a mathematical structure that has addition, a 0, multiplication, a 1, and a reciprocal for every non-0 element.
Abstract algebra to the rescue! (Math seems to rescue computer science a lot.) It turns out that there is a field with 256 elements known as GF(2**8). In this field, 0 is the 0, 1 is the 1 (surprise!), addition is bitwise exclusive-or (so every number is its own additive inverse!), and multiplication is a weird, and seemingly unpredictable beast, that is best calculated by pre-populating a table of logarithms and exponents, then creating a 256×256 array containing the multiplication table (since each number fits in a byte, the whole table only takes 64K).
[There are actually lots of ways to define multiplication that still meets the requirements of a field, but we have to pick one by defining what’s called the irreducible polynomial for the field.]
Once we operate over this field, all matrix values are guaranteed to be in the range [0, 255], and our method for bytewise encoding and decoding becomes easy.
One more aside: zfec actually piles the 3×3 (well, KxK) identity matrix on top of the Vandermonde matrix, so the first K pieces are exactly what you’d get by cutting the file into K pieces in the obvious way and putting the tiny header in front. Even though our matrix is no longer a Vandermonde matrix, submatrices are still guaranteed to be invertible and it still works.